ZooKeeper Standalone 模式启动分析
Zookeeper服务启动
ZooKeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负债均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
从本质上,Zookeeper类似一个分布式的存储系统,通过以Leader-Followers的模式运行的集群来实现高可用。本文主要分析单机模式的zk的启动流程。
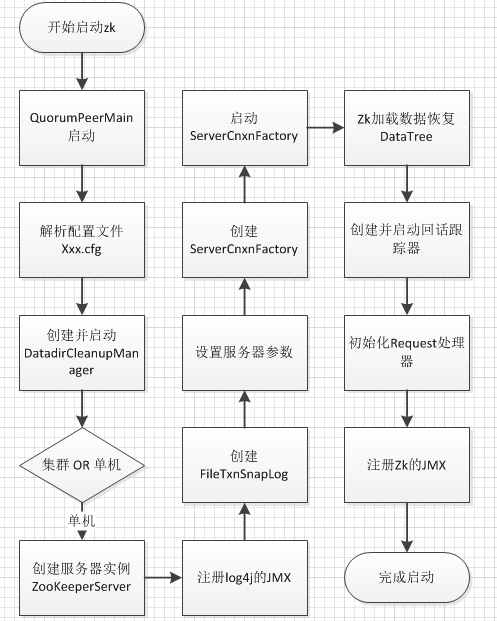
启动入口分析
以Windows下的启动例子,找到zkServer.cmd,主要的内容为
1
2
3
4
5
# zkServer.cmd
set ZOOMAIN=org.apache.zookeeper.server.quorum.QuorumPeerMain
echo on
call %JAVA% "-Dzookeeper.log.dir=%ZOO_LOG_DIR%" "-Dzookeeper.root.logger=%ZOO_LOG4J_PROP%" -cp "%CLASSPATH%" %ZOOMAIN% "%ZOOCFG%" %*
可以找到启动的Main类为QuorumPeerMain,参数为ZOOCFG,也就是zk的配置文件路径。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// QuorumPeerMain
/**
* zk 接收config配置启动
*/
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
main.initializeAndRun(args);
}
/**
* 初始化zk,并运行
*/
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// Start and schedule the the purge task
// 清理txnlog 和snapshot
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
if (args.length == 1 && config.servers.size() > 0) {
runFromConfig(config);
} else {
// 单机模式
ZooKeeperServerMain.main(args);
}
}
可以看出,QuorumPeerMain中,完成了DatadirCleanupManager的创建和运行,并将单机启动的工作交给ZooKeeperServerMain进行处理。
清理snapshot和TxnLog
DatadirCleanupManager的主要工作是定期清理snapshot和snapshot对应的TxnLog,可以通过zoo.cfg中的autopurge.purgeInterval和autopurge.snapRetainCount来调整执行频率和需要保留的snapshot数量。
TxnLog记录了zk接收到的事务请求,zk的事务指的是会影响zk服务器状态的操作,包括节点的创建、节点数据的更新、回话的创建和关闭、节点quota的配置等,每一个事务操作都会被记录到TxnLog中,并分配一个zxid,zxid是全序并且唯一的。整个zk实际上也是一个状态机,如果将所有的TxnLog在两台全新的zk上执行,得到的状态是完全一致的。为了提高zk性能,在运行时,会将所有的数据存储在内存中。但是每一次重启后内存中的数据就会消失。zk会在数据恢复节点从TxnLog中奖所有的事务节点执行一遍。但是显然随着TxnLog的增长这样的效率会变得越来越差,因此zk会每隔一段时间或者在处理一定数量的事务之后,将内存中的数据序列化后写入到磁盘中作为恢复快照。这样重启恢复数据的时候,只需要将snapshot先反序列化之后读入磁盘,再将部分TxnLog进行重放,即可快速恢复数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
//DatadirCleanupManager
public void start() {
if (PurgeTaskStatus.STARTED == purgeTaskStatus) {
LOG.warn("Purge task is already running.");
return;
}
// Don't schedule the purge task with zero or negative purge interval.
if (purgeInterval <= 0) {
LOG.info("Purge task is not scheduled.");
return;
}
timer = new Timer("PurgeTask", true);
TimerTask task = new PurgeTask(dataLogDir, snapDir, snapRetainCount);
timer.scheduleAtFixedRate(task, 0, TimeUnit.HOURS.toMillis(purgeInterval));
purgeTaskStatus = PurgeTaskStatus.STARTED;
}
DatadirCleanupManager启动之后,会启动一个定时器,通过PurgeTask将可以清理的snapshot和对应的TxnLog清理掉。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
//PureTxnLog
public static void purge(File dataDir, File snapDir, int num) throws IOException {
if (num < 3) {
throw new IllegalArgumentException(COUNT_ERR_MSG);
}
FileTxnSnapLog txnLog = new FileTxnSnapLog(dataDir, snapDir);
List<File> snaps = txnLog.findNRecentSnapshots(num);
retainNRecentSnapshots(txnLog, snaps);
}
// VisibleForTesting
static void retainNRecentSnapshots(FileTxnSnapLog txnLog, List<File> snaps) {
// found any valid recent snapshots?
if (snaps.size() == 0)
return;
File snapShot = snaps.get(snaps.size() -1);
final long leastZxidToBeRetain = Util.getZxidFromName(
snapShot.getName(), PREFIX_SNAPSHOT);
class MyFileFilter implements FileFilter{
private final String prefix;
MyFileFilter(String prefix){
this.prefix=prefix;
}
public boolean accept(File f){
if(!f.getName().startsWith(prefix + "."))
return false;
long fZxid = Util.getZxidFromName(f.getName(), prefix);
// 根据文件的末尾zxid标记判断是否删除
if (fZxid >= leastZxidToBeRetain) {
return false;
}
return true;
}
}
// add all non-excluded log files
List<File> files = new ArrayList<File>(Arrays.asList(txnLog
.getDataDir().listFiles(new MyFileFilter(PREFIX_LOG))));
// add all non-excluded snapshot files to the deletion list
files.addAll(Arrays.asList(txnLog.getSnapDir().listFiles(
new MyFileFilter(PREFIX_SNAPSHOT))));
// remove the old files
for(File f: files)
{
System.out.println("Removing file: "+
DateFormat.getDateTimeInstance().format(f.lastModified())+
"\t"+f.getPath());
if(!f.delete()){
System.err.println("Failed to remove "+f.getPath());
}
}
}
PureTask通过PurgeTxnLog进行文件的清理。因此snapshot和txnlog的后缀都是全序的zxid,因此可以通过zxid进行判断和过滤。
启动和初始化工作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
//ZooKeeperServerMain
/**
* 单机启动
*/
protected void initializeAndRun(String[] args)
throws ConfigException, IOException
{
try {
//通过JMX来设置log4j的配置
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
// zoo.cfg 作为初始化条件
ServerConfig config = new ServerConfig();
if (args.length == 1) {
config.parse(args[0]);
} else {
config.parse(args);
}
runFromConfig(config);
}
/**
* 开始启动
* Run from a ServerConfig.
* @param config ServerConfig to use.
* @throws IOException
*/
public void runFromConfig(ServerConfig config) throws IOException {
LOG.info("Starting server");
FileTxnSnapLog txnLog = null;
try {
ZooKeeperServer zkServer = new ZooKeeperServer();
// 创建txn log文件
txnLog = new FileTxnSnapLog(new File(config.dataLogDir), new File(
config.dataDir));
zkServer.setTxnLogFactory(txnLog);
//心跳频率
zkServer.setTickTime(config.tickTime);
// session超时
zkServer.setMinSessionTimeout(config.minSessionTimeout);
zkServer.setMaxSessionTimeout(config.maxSessionTimeout);
// Zk 默认的通信使用过的原生的NIO 可以通过环境变量设置为Netty
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
// zk服务
cnxnFactory.startup(zkServer);
cnxnFactory.join();
if (zkServer.isRunning()) {
zkServer.shutdown();
}
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Server interrupted", e);
} finally {
if (txnLog != null) {
txnLog.close();
}
}
}
zk使用log4j和slf4j作为日志组件,可以通过JMX进行运行时监控和管理。
snapshot和txnlog是zk文件管理的核心,FileTxnSnapLog封装了对snapshot和txnlog的操作接口。在整个zk运行过程中,都是通过这个类来对snapshot和txnlog进行处理,包括了txn的写入、删除、以及zk恢复阶段的核心操作。
zk在启动之后,通过网络对外提供服务,zk提供了两个网络通信框架:分别是Netty3和NIO,默认使用NIO,可以通过zookeeper.serverCnxnFactory系统属性进行修改,实际上Netty也是基于NIO实现。实际的实现类为NIOServerCnxnFactory。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
/**
* 启动 zkserver
*/
@Override
public void startup(ZooKeeperServer zks) throws IOException,
InterruptedException {
// 设置线程状态为启动,并开始NIO监听客户端请求
start();
// 设置Zookeeper Server
setZooKeeperServer(zks);
// 加载恢复数据
zks.startdata();
// 处理启动
zks.startup();
}
//监听zk client的请求
public void run() {
while (!ss.socket().isClosed()) {
try {
// 1s
selector.select(1000);
Set<SelectionKey> selected;
synchronized (this) {
selected = selector.selectedKeys();
}
ArrayList<SelectionKey> selectedList = new ArrayList<SelectionKey>(
selected);
Collections.shuffle(selectedList);
for (SelectionKey k : selectedList) {
if ((k.readyOps() & SelectionKey.OP_ACCEPT) != 0) {
//连接
SocketChannel sc = ((ServerSocketChannel) k
.channel()).accept();
//client ip
InetAddress ia = sc.socket().getInetAddress();
int cnxncount = getClientCnxnCount(ia);
// 限制客户端连接数
if (maxClientCnxns > 0 && cnxncount >= maxClientCnxns) {
LOG.warn("Too many connections from " + ia
+ " - max is " + maxClientCnxns);
sc.close();
} else {
LOG.info("Accepted socket connection from "
+ sc.socket().getRemoteSocketAddress());
sc.configureBlocking(false);
//Channel READ
SelectionKey sk = sc.register(selector,
SelectionKey.OP_READ);
//将cnxn作为存储附件
NIOServerCnxn cnxn = createConnection(sc, sk);
sk.attach(cnxn);
addCnxn(cnxn);
}
} else if ((k.readyOps() & (SelectionKey.OP_READ | SelectionKey.OP_WRITE)) != 0) {
// 读写请求
NIOServerCnxn c = (NIOServerCnxn) k.attachment();
// 处理请求
c.doIO(k);
} else {
if (LOG.isDebugEnabled()) {
LOG.debug("Unexpected ops in select "
+ k.readyOps());
}
}
}
selected.clear();
} catch (RuntimeException e) {
LOG.warn("Ignoring unexpected runtime exception", e);
} catch (Exception e) {
LOG.warn("Ignoring exception", e);
}
}
closeAll();
LOG.info("NIOServerCnxn factory exited run method");
}
NIOServerCnxnFactory创建了一个NIO Server,创建连接之后,将NIO通信封装为NIOServerCnxn作为附件存放在SelectionKey中,并在客户端请求到达之后取出进行后续的请求处理。后续会专门有来讨论这个流程。
数据恢复
数据恢复是zk启动服务的关键步骤,通过先前创建的FileTxnSnapLog对象中包含的snapshot和txnlog重新构建内存DataTree。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// ZooKeeperServer
/**
* 初始化数据
*
* @throws IOException
* @throws InterruptedException
*/
public void startdata()
throws IOException, InterruptedException {
//check to see if zkDb is not null
if (zkDb == null) {
// 根据snapshot创建zbdb
zkDb = new ZKDatabase(this.txnLogFactory);
}
if (!zkDb.isInitialized()) {
loadData();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// ZkDataBase
/**
* 从磁盘中还原数据到DataTree
*/
public long loadDataBase() throws IOException {
// 每次执行一个Transaction之后,就放入commited log中,
// 便于在其他的Follower中快速恢复
PlayBackListener listener=new PlayBackListener(){
public void onTxnLoaded(TxnHeader hdr,Record txn){
Request r = new Request(null, 0, hdr.getCxid(),hdr.getType(),
null, null);
r.txn = txn;
r.hdr = hdr;
r.zxid = hdr.getZxid();
addCommittedProposal(r);
}
};
long zxid = snapLog.restore(dataTree,sessionsWithTimeouts,listener);
initialized = true;
return zxid;
}
这边创建了一个回调监听PlayBackListener,通过这个回调监听,可以向ZkDatabase中的commitedLog中追加Transaction记录,这样就可以将在本Server中回放的Transaction快速复制到其他的Follower机器上快速恢复。
而具体恢复数据的方法在FileTxnSnapLog中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
/**
* 从snapshot和transaction log中恢复zk server的数据
* 这个方法返回恢复后最高的zxid
*/
public long restore(DataTree dt, Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
// 将snapshot写入到data tree中
snapLog.deserialize(dt, sessions);
// Transaction Log
FileTxnLog txnLog = new FileTxnLog(dataDir);
// 从最后一个处理过的Transaction Record开始继续处理
TxnIterator itr = txnLog.read(dt.lastProcessedZxid+1);
// 已经处理过的Transaction中编号最大的
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
try {
while (true) {
// iterator points to
// the first valid txn when initialized
hdr = itr.getHeader();
if (hdr == null) {
//empty logs
// txnLog 已经没有更多的 transaction
return dt.lastProcessedZxid;
}
if (hdr.getZxid() < highestZxid && highestZxid != 0) {
LOG.error("{}(higestZxid) > {}(next log) for type {}",
new Object[] { highestZxid, hdr.getZxid(),
hdr.getType() });
} else {
highestZxid = hdr.getZxid();
}
try {
// 在Data Tree 中执行Transaction 恢复
processTransaction(hdr,dt,sessions, itr.getTxn());
} catch(KeeperException.NoNodeException e) {
throw new IOException("Failed to process transaction type: " +
hdr.getType() + " error: " + e.getMessage(), e);
}
listener.onTxnLoaded(hdr, itr.getTxn());
if (!itr.next())
break;
}
} finally {
if (itr != null) {
itr.close();
}
}
// 返回最大的zxid
return highestZxid;
}
主要有两个步骤:
- 将snapshot直接反序列化到DataTree中,并获取当前DataTree中最高的zxid
- 通过zxid从TxnLog中找到在zxid之后,记录到TxnLog中的事务,并将这些事务取出重新执行。
zk对于数据恢复的设计非常巧妙。为了保证zk在进行snapshot操作的时候能够持续服务,就必须使得zk在snapshot期间依然可以写入数据。而在恢复阶段,为了保证数据的完整性,则必须处理在快照之后,补充写入snapshot之后的发生事务。因此必须要有一个标识能够识别那些是snapshot之前,那些是snapshot之后的事务。在这边zk巧妙利用了zxid的全局唯一,以及全序性特征。在恢复snapshot到DataTree之后,就可以获取到最大的zxid,lastZxid,这个无疑是snapshot中最后一个执行的事务的zxid,通过这个zxid,找到从所有的txnlog中搜索zxid大于等于这个lastid的事务,并将事务重新在DataTree中写入,即可保证数据的完整性。从这边也可以看出,zxid在整个zk服务中的重要地位。
启动处理器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// ZooKeeperServer
/**
* 启动zk
*/
public synchronized void startup() {
if (sessionTracker == null) {
createSessionTracker();
}
// session追踪,处理session超时等
startSessionTracker();
// 请求处理器
setupRequestProcessors();
// 注册jmx,可以通过jmx获取zkDatabase的一些信息
registerJMX();
// 修改运行状态
state = State.RUNNING;
notifyAll();
}
整个启动流程的最后一步,首先创建SessionTracker,用于周期性检查session的过期情况。在实现类SessionTrackerImpl内部实际上维护另一个HashMap,对连接到本机的client sesison进行定期检查。
关键步骤是初始化和执行请求处理器
1
2
3
4
5
6
7
8
9
10
11
/**
* 设置请求处理器
*/
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
zk对于request的处理,使用调用链模式,PrepRequestProcessor、SyncRequestProcessor、FinalRequestProcessor构成调用链,并依次对request进行处理。
首先是PrepRequestProcessor,主要完成的工作是用Request构建待处理的Transaction。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
while (true) {
// 循环处理 submitted Requests中的数据
Request request = submittedRequests.take();
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'P', request, "");
}
if (Request.requestOfDeath == request) {
break;
}
pRequest(request);
}
protected void pRequest(Request request) throws RequestProcessorException {
// LOG.info("Prep>>> cxid = " + request.cxid + " type = " +
// request.type + " id = 0x" + Long.toHexString(request.sessionId));
request.hdr = null;
request.txn = null;
try {
switch (request.type) {
case OpCode.create:
// 请求
CreateRequest createRequest = new CreateRequest();
pRequest2Txn(request.type, zks.getNextZxid(), request, createRequest, true);
break;
// 略
}
}
request.zxid = zks.getZxid();
// 下一个 processor 进行处理
nextProcessor.processRequest(request);
}
protected void pRequest2Txn(int type, long zxid, Request request, Record record, boolean deserialize) throws KeeperException, IOException, RequestProcessorException {
request.hdr = new TxnHeader(request.sessionId, request.cxid, zxid,
zks.getTime(), type);
switch (type) {
case OpCode.create:
// 检查session是否有效
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
CreateRequest createRequest = (CreateRequest)record;
if(deserialize)
// 将request反序列化为 createRequest
ByteBufferInputStream.byteBuffer2Record(request.request, createRequest);
//需要创建的 path
String path = createRequest.getPath();
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1 || path.indexOf('\0') != -1 || failCreate) {
LOG.info("Invalid path " + path + " with session 0x" +
Long.toHexString(request.sessionId));
throw new KeeperException.BadArgumentsException(path);
}
//权限控制
List<ACL> listACL = removeDuplicates(createRequest.getAcl());
if (!fixupACL(request.authInfo, listACL)) {
throw new KeeperException.InvalidACLException(path);
}
//父亲节点
String parentPath = path.substring(0, lastSlash);
ChangeRecord parentRecord = getRecordForPath(parentPath);
checkACL(zks, parentRecord.acl, ZooDefs.Perms.CREATE,
request.authInfo);
int parentCVersion = parentRecord.stat.getCversion();
CreateMode createMode =
CreateMode.fromFlag(createRequest.getFlags());
if (createMode.isSequential()) {
// 处理seq节点
path = path + String.format(Locale.ENGLISH, "%010d", parentCVersion);
}
// check
validatePath(path, request.sessionId);
try {
//已经存在,则不允许重复创建
if (getRecordForPath(path) != null) {
throw new KeeperException.NodeExistsException(path);
}
} catch (KeeperException.NoNodeException e) {
// ignore this one
}
//父亲节点不允许创建子节点
boolean ephemeralParent = parentRecord.stat.getEphemeralOwner() != 0;
if (ephemeralParent) {
throw new KeeperException.NoChildrenForEphemeralsException(path);
}
int newCversion = parentRecord.stat.getCversion()+1;
//构造request中的transaction
request.txn = new CreateTxn(path, createRequest.getData(),
listACL,
createMode.isEphemeral(), newCversion);
StatPersisted s = new StatPersisted();
if (createMode.isEphemeral()) {
//临时节点
s.setEphemeralOwner(request.sessionId);
}
// parent 的修改和 children节点的修改,共享一个zxid
parentRecord = parentRecord.duplicate(request.hdr.getZxid());
parentRecord.childCount++;
parentRecord.stat.setCversion(newCversion);
// 添加到待处理的 change record中,继续后续的processor
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.hdr.getZxid(), path, s,
0, listACL));
break;
// 略
代码较长,摘出来的代码中主要以创建节点为例子,最终讲request构建成ChangeRecord并调用nextProcessor.processRequest()将request写入SyncRequestProcessor的待处理请求队列queuedRequests中,继续剩下的工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
int logCount = 0;
// we do this in an attempt to ensure that not all of the servers
// in the ensemble take a snapshot at the same time
// 避免所有的servers同时进行快照转储
setRandRoll(r.nextInt(snapCount/2));
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = queuedRequests.poll();
if (si == null) {
flush(toFlush);
continue;
}
}
if (si == requestOfDeath) {
break;
}
if (si != null) {
// track the number of records written to the log
if (zks.getZKDatabase().append(si)) {
// 添加成功
logCount++;
// 是否要进行 snapshot
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);
// roll the log
zks.getZKDatabase().rollLog();
// take a snapshot
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
// create snapshot
snapInProcess.start();
}
logCount = 0;
}
} else if (toFlush.isEmpty()) {
// optimization for read heavy workloads
// iff this is a read, and there are no pending
// flushes (writes), then just pass this to the next
// processor
// 对于读请求,直接转发给下一个Processor进行处理
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
continue;
}
// 批量刷盘
toFlush.add(si);
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
SyncRequestProcessor的功能相对简单,主要是讲Request追加到TxnLog中,并决定是否对当前的ZkDatabase进行快照转储。
最后在FinalRequestProcessor中,讲Request真正应用到DataTree中,并根据请求的内容,构建出返回Response,通过ServerCnxn,返回给请求客户端。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// 读取值
lastOp = "GETD";
GetDataRequest getDataRequest = new GetDataRequest();
ByteBufferInputStream.byteBuffer2Record(request.request,
getDataRequest);
// 从DataTree中读取DataNode
DataNode n = zks.getZKDatabase().getNode(getDataRequest.getPath());
if (n == null) {
throw new KeeperException.NoNodeException();
}
Long aclL;
synchronized(n) {
aclL = n.acl;
}
PrepRequestProcessor.checkACL(zks, zks.getZKDatabase().convertLong(aclL),
ZooDefs.Perms.READ,
request.authInfo);
// 请求路径对应的状态
Stat stat = new Stat();
// 获取请求路径的内容
byte b[] = zks.getZKDatabase().getData(getDataRequest.getPath(), stat,
getDataRequest.getWatch() ? cnxn : null);
rsp = new GetDataResponse(b, stat);
到这边就完成了RequestProcessor调用链的整个处理周期,可以看出,zk首先对请求进行分类,再写入到事务日志中,最后才进行正常的读写DataTree处理。只有完成这三个步骤之后,一个请求的生命周期才算完成。代码方面,三个处理器之间使用有序队列来进行交互,可以有地减少代码耦合;调用链模式的引入,也有利于后续的拓展。