ZooKeeper Leader选举
ZooKeeper选举过程
为了实现zookeeper的高可用,一般会以集群的方式来搭建。集群机器的数量一般为2n+1台,在zoo.cfg中进行配置,具体可以参考Zookeeper Admin。
在集群运行下zk使用了一种leader-follower的模式运行
- 从集群中选举出一台Leader,在正常情况下Leader有且仅有一台,其他的服务器作为follower的角色
- 客户端随机连接到一台机器进行读写,如果连接到的服务器是follower,则写请求会被follower转发到leader服务器完成
- leader统一处理写入请求,而且leader的写入请求必须在超过半数的服务器(包括自己)中生效之后,才算成功,整个写入过程使用两阶段提交
- 当半数的follower和leader失去联系之后,就会重新进入新一轮的选举流程
可知,leader-election在整个zk运行时候的重要地位,zk设计了zab算法来实现leader-election以及后续的客户端请求处理。在leader-election环节,zab和paxos算法具有很多类似的地方,本文主要记录zookeeper在进行leader-election的技术细节。
关键的类
QuorumPeer集群模式下zk服务QuorumPeerMain集群模式下的zk服务启动入口QuorumCnxManager使用tcp协议管理leader-election中的网络IOFastLeaderElectionzk默认的选举算法
从大的流程看
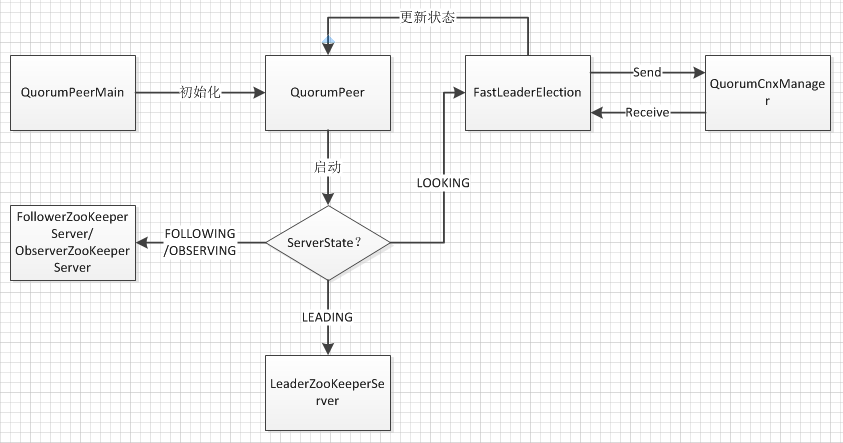
整个选举的核心流程在于FastLeaderElection如何通过QuorumCnxManager使用消息传递在集群中选举出唯一的Leader,之后跟新QuorumPeer的状态,并根据状态创建服务的对应服务。FastLeaderElection的这个功能和Basic Paxos非常的类似:在一个分布式集群中,通过消息通信达成一个确定的值,在这边这个值就是leader的服务器编号。下面以自顶向下的模式,分析整个启动和选举的实现细节。
状态迁移
前面已经说到,在集群中服务器会处于不同的状态,这些状态决定了在集群中服务器的功能和作用,zk把状态定义为四种
1
2
3
public enum ServerState {
LOOKING, FOLLOWING, LEADING, OBSERVING;
}
- LOOKING 查找状态,发起leader-election
- FOLLOWING 跟随状态,可以对外提供读写服务,其中写服务转发给leader处理;
- LEADING 领导状态,处理集群中的读写请求,遵循半数写入生效原则
- OBSERVING 观察状态,不具备投票权的Follower
QuorumPeer启动的时候,默认状态为LOOKING,启动后首先进入选举模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
/*
* Main loop
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
// 状态looking进入选举流程
if (Boolean.getBoolean("readonlymode.enabled")) {
//是否开启只读模式
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(
logFactory, this,
new ZooKeeperServer.BasicDataTreeBuilder(),
this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
setBCVote(null);
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
setBCVote(null);
//开始选举,从FastLeaderlection中选举出Leader
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
observer.shutdown();
setObserver(null);
setPeerState(ServerState.LOOKING);
}
break;
case FOLLOWING:
// 处于following模式下
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
// 如果跟随出现了偏差,再次进入LOOKING模式
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
}
}
整个运行过程中,zk都会在这个循环体中,根据集群的变化,改变自己的状态,并根据状态调整自己在集群中的角色。本次主要描述LOOKING状态下leader-election流程;对于其他三种状态,在正常情况下会分别初始化出对应的ZooKeeperServer并运行,在出现异常的情况下,会关闭并重新进入LOOKING状态。
在LOOKING状态下,核心的代码为
1
setCurrentVote(makeLEStrategy().lookForLeader());
通过这一句代码来启动FastLeaderElection的leader-election流程。
网络管理
在开始分析选举流程之前,先对网络管理做一下介绍。zk为了保证消息传输的有序性,使用tcp作为传输层协议。主要的逻辑都在QuorumCnxManager中,QuorumCnxManager在内部维护了三个内部类来实现网络通信。
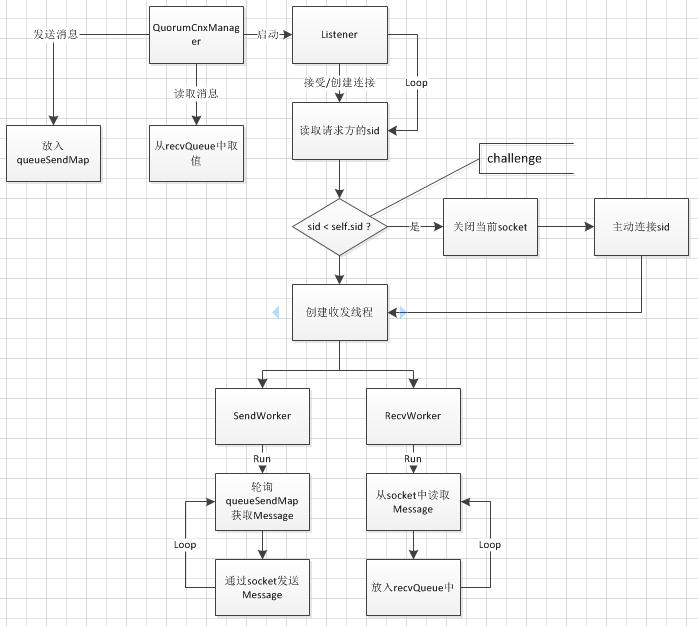
QCM为本机和集群中的所有server维护了一个以sid为key,sendworker为value的ConcurrentHashMap:senderWorkerMap;以及sid为key,message列表为value的待发送ConcurrentHashMap:queueSendMap,一个用于存放本机接受到的消息的ArrayBlockingQueue:recvQueue。
每和一个server创建连接,都会根据连接到的sid创建两个独立运行的线程SendWorker和RecvWorker。每一个SendWorker会一直轮询写入到queueSendMap中对应自己sid消息列表的数据,并通过socket发送;RecvWorker则会一直监听写入到socket中的消息,并将读取到的消息直接存放入recvQueue中。
QCM对外提供的读取和发送接口,都是异步完成的将需要发送的数据,写入到queueSendMap中,读取数据数据的时候,从recvQueue获取。
在创建连接的时候,会引入一个冲突检测机制,主要的原因是一对机器可能会同时申请和对方创建连接,如果都接受的话,显然会照成资源的浪费。因此qcm只允许sid较大的server向sid较小的sid创建连接。
选举流程
接下来分析一下FastLeaderElection的主要流程

选举的入口为lookForLeader,整个大体流程并不难理解,先给自己投票即声明自己希望成为Leader并作为提案广播给集群内的其他server。集群内的机器刚开始都是平等的,因此其他机器也会做同样的事情,所以你既会发送消息,也会接受消息。实际上自己发送出去的消息,自己也会收到,在这边发送和接收完全可以独立出来认为是两个不同的角色,只是刚好是同一台机器。
接下来就是处理收到的消息,这边有一个分支流程,如果没有收到消息,可能是因为服务器之间还没有创建连接,因此调用QuorumCxnManager,主动连接其他服务器。收到消息之后,首先判断消息的类型,如果是OBSERVING,显然这些机器是不具备投票资格的,可以直接忽略读取下一个消息;如果是LEADING或者FOLLOWING,表示其他的机器可能已经选举处理leader,需要进行进一步的校验;如果是LOOKING,表示这也是一个提案消息,需要进一步进行校验判断。
这边需要重点解释几个变量的意思
- FastLeaderElection成员变量logicalclock:这个变量标识了选举的轮次,保存在内存中,初始化为0,每进行一次选举,也就是
QuorumPeer调用FastLeaderElection的lookForLeader方法,这个值会递增+1。这个变量的主要作用是保证任何一次有效的选举,需要投票都是在同一个轮次中。不同轮次的消息不应该相互影响。 - FastLeaderElection成员变量recvqueue:记录了FastLeader在选举过程中接受到的消息,就是从qcm中获取到消息,存入这个队列中。
- lookForLeader方法局部变量
HashMap-recvset:保存本轮选举中(具有相同的logicalclock)收到的消息,recvset的功能主要是在判断投票是否成功(半数一致)。 - lookForLeader方法局部变量
HashMap-outofelection:记录了状态为LEADING或者FOLLOWING状态的服务器的消息,这些消息一般表明选举已经完成了选举,通过校验outofelection的有效性即可验证leader选举的结果。
理清楚这几个主要的变量之后,进入LOOKING流程分析
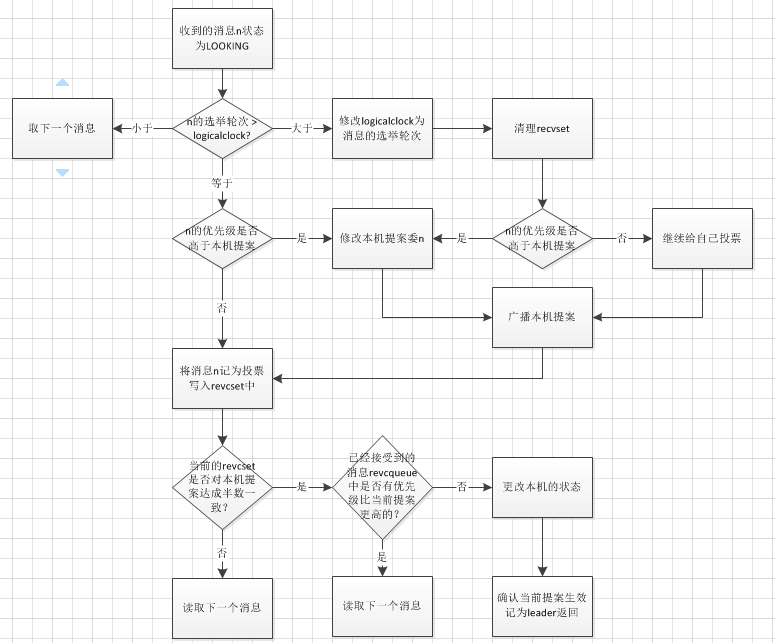
首先必须保证选举中的选票都必须在同一个轮次中投出,如果收到的消息轮次大于本机logicalclock,则将之前的选票丢弃,并修改本机logicalclock,相当于重新进行一次选举;如果小于的话,证明这个消息对应的服务器可能刚刚加入,直接丢弃即可,该服务器稍后就会收到本机广播出去的消息调整自己的logicalclock;对于轮次相等和大于的情况,还需要比较消息和本机提案的优先级,如果优先级高于本机,则将本机的提案内容修改为消息的提案内容,并在此对外广播提案。这里的优先级比较,隐含了zk选举的一个重要前提,就是选举出来的leader必须拥有所有server中最全的数据,也就是最大的zxid,因此zxid更高的消息,拥有更高的优先级。
接着对revcset中的选票进行统计,如果有半数选择了本机目前的提案,并且未处理的消息中,没有优先级更高的提案,则将当前提案中的sid对应的server选中为leader,根据sid修改自身的状态结束选举,返回选举结果;否则继续读取消息处理。
在这个校验未处理队列是否有更优先的消息的代码中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// Verify if there is any change in the proposed leader
while ((n = recvqueue.poll(finalizeWait,
TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)) {
// 1. 如果新收到的消息中有比之前消息优先级更高的消息,则跳出循环,意味着这次半数投票无法生效
// 核心的问题在于,zk的选举必须要保证选举出来的leader具有最大的zxid
recvqueue.put(n);
break;
}
}
/**
* This predicate is true once we don't read any new
* relevant message from the reception queue
* 如果n == null,可知 1. 并未执行
*/
if (n == null) {
// 修改自己的状态为Leader或者是Leanner
self.setPeerState((proposedLeader == self.getId()) ?
ServerState.LEADING : learningState());
// 最终选票
Vote endVote = new Vote(proposedLeader,
proposedZxid,
logicalclock,
proposedEpoch);
leaveInstance(endVote);
return endVote;
}
finalizeWait的作用,主要是为了增加等待的时间,避免在recvqueue.poll后,又马上又新的消息送达,出现下面的情况:
接收到一个优先级更高的notification,为了简单描述,假设这个notification最后被majority的机器接受 这样一次执行后,可能会出现不收敛的情况
情况1:选举自己为LEADER,则显然,这个LEADER在后面的lead()中无法得到majority机器的NEWLEADER响应,重新进入选举 情况2:选举出自己为FOLLOWER,则必然有一个LEADER被选举出来,而且这个LEADER也会出现情况1,无法称为正常的LEADER,因此本机重新进入选举。
finalizeWait时间的加入,减少了出现不收敛的可能性。
进入FOLLOWING和LEADING的流程分析

有消息状态为FOLLOWING或者LEADING,表明在集群中已经选举达成了一致状态,因此本机的主要工作是校验,从接受到的消息中校验选举的有效性,校验的主要方法是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
protected boolean ooePredicate(HashMap<Long, Vote> recv,
HashMap<Long, Vote> ooe,
Notification n) {
/**
* termPredicate 首先判断recv中是否有半数成员对 n 提案达成一致
* checkLeader 判断ooe中以及该选择出的leader处于LEADING的状态
*/
return (termPredicate(recv, new Vote(n.version,
n.leader,
n.zxid,
n.electionEpoch,
n.peerEpoch,
n.state))
&& checkLeader(ooe, n.leader, n.electionEpoch));
}
protected boolean termPredicate(
HashMap<Long, Vote> votes,
Vote vote) {
//校验半数通过vote
HashSet<Long> set = new HashSet<Long>();
/*
* First make the views consistent. Sometimes peers will have
* different zxids for a server depending on timing.
*/
for (Map.Entry<Long, Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())) {
set.add(entry.getKey());
}
}
return self.getQuorumVerifier().containsQuorum(set);
}
protected boolean checkLeader(
HashMap<Long, Vote> votes,
long leader,
long electionEpoch) {
boolean predicate = true;
/**
* 自己是leader,或者votes中有server声明自己是leader
*/
if (leader != self.getId()) {
if (votes.get(leader) == null) {
predicate = false;
} else if (votes.get(leader).getState() != ServerState.LEADING) {
predicate = false;
}
} else if (logicalclock != electionEpoch) {
predicate = false;
}
return predicate;
}
很显然,选举出来的leader首先需要满足半数一致,而且这个半数消息必须被本机接受到,并且outofelection中选中的leader必声明自己的状态LEADING。
选举之后
选举之后,本机可以知道两个信息,1.本机的角色;2.如果本机的角色是follower,还会知道leader机器的sid;根据这两个信息,就可以进行具体的服务初始化过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
case FOLLOWING:
// 处于following模式下
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
// 如果跟随出现了偏差,再次进入LOOKING模式
follower.shutdown();
setFollower(null);
setPeerState(ServerState.LOOKING);
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
setPeerState(ServerState.LOOKING);
}
break;
follower主要完成
- 创建和leader的连接
- 和leader同步事务
- 启动
FollowerZooKeeperServer服务
FollowerZooKeeperServer本身也是一个ZooKeeperServer只是其处理器会有不同,firstProcessor会将请求转发给leader服务器进行处理。
leader主要完成的工作
- 向其他的服务器发出NEWLEADER确认信息,等待半数确认后,正式成为leader
- 启动
LeaderZooKeeperServer,剩下的工作和单机的zk类似 - 在事务提交的时候,需要等待majority的服务器确认后才能提交
总结
zab协议分散在zk的各个地方,FastLeaderElection的主要目标是从消息中识别出一个zxid最大的消息,并确认这个消息被集群中的的大多数机器接受,确认为leader。这个paxos算法的功能类似,但是也有一些差异。Zab vs Paxos,有做了详细的描述。
- paxos主要用于状态机中的日志复制,强调只要每个节点上的log内容一致,即每一个副本上的内容和顺序一致,那么重放得到的最终状态一致。
- paxos,特指引入leader角色的multi paxos。为了提高让客户端能同时提交决议,举个例子,假设有27、28、29三个位置需要填充数据。paxos为了同时对这三个位置进行表决,引入了时间窗的概念,在一个时间窗内可以并行或者重叠提交多个提案,那自然可能部分提交成功部分提交失败的例子,新的leader选举之后,可以使用任意的顺序恢复之前的提案,paxos的目标只是保证各个副本的值是一致的,并不保证这些值逻辑上的顺序。
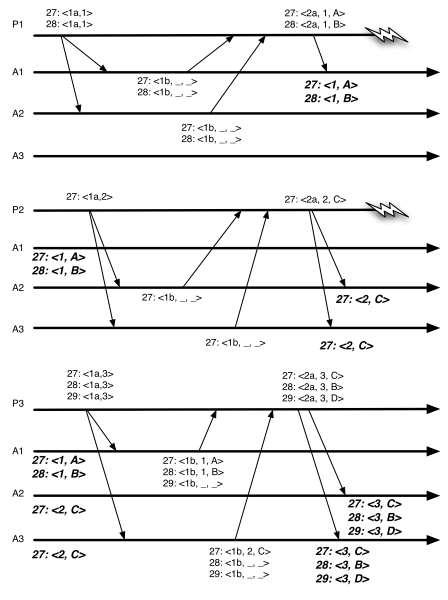
P1 P2 P3 分别作为不同阶段的Leader
- P1在Phase1对A1和A2发出 27<1a,1>,28<1a,1>的预提案,A1和A2此前没有接受过任何的值因此会保证不会再响应 ballot<1 的提案
- P1得到promise之后,发起提案,27<1a,1,A> 28<1a,1,B>,这时候只有A1接受了提案,P1出现故障,但是A2未接受。
- P2在Phase1对A2和A3发出 27<1a,2>的预提案,并在Phase2顺利提交27<2a,2,C>,使得27的值为C,P2出现故障。
- P3在Phase1对A1和A3发出 27<1a,3>,28<1a,3>,29<1a,3>预提案,此时A1会返回之前接受到的P1的提案值,27<1b,1,A>和28<1b,1,B>,A3则会返回27<1b,2,C>..,最终P3会对27、28、29达成27<3,C>,28<3,B>的状态,这样A作为未提交的状态就丢失了,而状态C则出现在B之前。
- zab则是用于主备primary-backup模型下的多副本一致性协议,并且副本中的事务存在逻辑上的依赖关系,除了副本内容一致之外,还需要保证内容内部的逻辑以来关系,也就是说对于上面这个例子来说,A必须要出现在B之前。
- paxos如果要做到保证逻辑以来,则必须关闭提交窗口,提交一个提案之前,必须保证之前的提案被提交,就可以保证严格按照状态迁移,也就是27的位置必须先提交,之后才能提交28的位置。当时这样性能很差
- zab则通过在恢复阶段增加一个同步过程,并使用zxid来保证总是能够获取最新的数据。从而保证逻辑上的以来关系,即zxid小的总是会先于zxid大的被提交。
zab和paxos的这些不同,可以看作是对paxos在leaner学习阶段的增强,而单纯的选举阶段,则和paxos基本是完全一致的。因此我们也可以认为zab就是paxos的一个实现版本。