多副本和分布式一致性
引文
对于一定规模的系统,都会对可拓展和高可用提出需求。针对一个包含应用层和存储层的典型系统来说,拓展也对应分成两个层次,应用层的拓展和存储层的拓展:
- 应用层的拓展主要是在系统设计上进行,目前选择的方案主要是构建无状态的应用系统,使得应用系统在整个业务逻辑中仅仅是一个处理过程,只要是相同的输入一定会有相同的输出和整个应用的上下文(时间、地点、人物)没有关系。部署上结合分布式部署和服务负载均衡就可以很好地解决应用层可拓展的问题。
- 对于存储层的拓展显然问题就复杂很多,应用层的拓展是基于无状态的服务作为前提,而存储本身就是一个巨大的状态机,数据前后相互依赖,因此在拓展方面先天不足。
让我们先从数据库拓展一个问题入手,怎么保证数据库的高可用。
假定单机数据库一定时间内出现故障的概率为98%,为了提高可用性一般会采用副本备份数据的方式,假设有N副本,则系统的可用性 >= 1 - (0.02 * N),可知,一般而言使用越多的副本备份,系统的可用性越高,这一点基本大家都能达成共识。
但是数据的备份不只是选择数据副本数量的问题,还需要保证
- 一致性:同一个时间从不同的副本读取数据能否一致?
- 可用性:局部的系统故障能否保证存储系统依然可用?
- 原子性:分布式事务问题
一致性包括两个维度,数据一致性:最终所有的数据都可以一致;视图一致性:从系统中读取的数据必须是一致的。
我们的目标是构建这样的系统:在保证数据一致性的前提下,提高可用性。既当系统写入数据之后,在系统局部出现故障的时候,系统中的副本依然能够提供准确的读写服务。
多副本复制
特定到使用多副本最多的数据库存储领域,我们来看看各种多副本解决方案,看能否满足我们的要求。
主从异步复制
也是我们接触最多的Master-Salve结构或者Primary-secondary结构,典型的应用比如MySQL的binlog复制
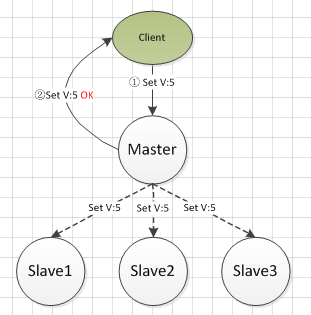
步骤:
- 主库接收写请求,将写请求写入到binlog中
- 主库完成请求,返回客户端请求执行成功
- 异步将数据从主库同步到其他从库,主要使用replay log重放技术
问题:
- 数据丢失问题:在主库本地操作完成到使用异步日志同步完成这段时间,如果主库的磁盘发生损坏,数据会永久丢失。
- 读一致性问题:使用异步复制的方法,在所有的副本同步完成前,如果只从一个库中读取数据,则这个库必须是Master才能保证读取到最新的数据。
实际上主从异步同步是最容易实现的模式,但是其核心问题在于数据丢失的问题,对于高频的业务系统,及时是1S的数据丢失都可能是致命的。
主从同步复制
这种方法是对异步复制遇到问题的改进,将异步修改为同步,典型的如MySQL的主备强同步,可以保证写入到系统中的数据不会出现丢失。
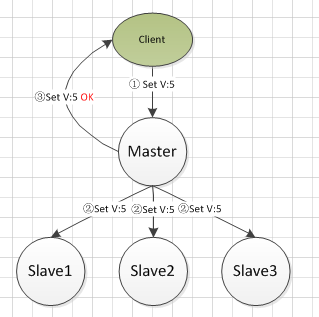
步骤:
- 主库接到写请求,写入到本地binlog中
- 主库复制日志到从库中
- 复制完成后,返回客户端执行成功
同步设计使得数据只有在所有的副本中都保存成功后才算真正完成写入,因此读取的时候,只要从任意一台机器上就可以读取到最新的数据,同时也不存在数据丢失的问题。
问题:可用性降低,每一次写入都需要所有备库参与,如果其中一部分备库不可用或者出现较长时间的延迟,则整个系统无法保证可用性。
主从半同步复制
这种方法是对同步复制方法的一个改善,保证最新的数据存储在至少主库+一台备库上,并且当一定数量的机器出现故障的时候,也可以保证系统可用。
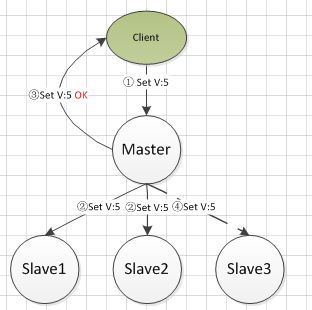
步骤:
- 主库接收写请求,并写入本地日志
- 主库复制日志到从库中
- 如果有X{1<=X<=N} 个从库返回写入完成,则认为操作完成,返回确认给到客户端
问题:从任意从库中读取数据的时候,无法保证读取到的是最新的数据。MySQL 得 semi-sync 就是使用这种策略,只需要一个从库返回 ack 即可认为事务提交成果。
多数派读写
少数服从多数,只要确保读写都得到半数节点的确认就认为写入和读取是可靠的,没有主库的概念,小于半数的节点发生故障的情况下,系统依然可用。典型的如Cassandra
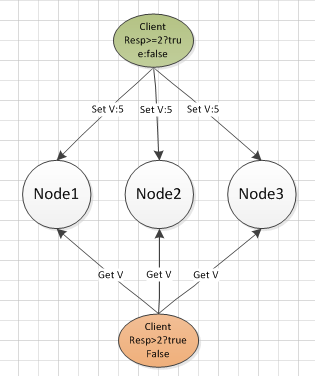
步骤:
- 客户端写入W >= N/2 +1个节点
- 读取的时候:W + R > N ; R >= N/2 + 1
- 最后一次写入会覆盖之前的写入
- 所有写入操作需要一个全局顺序:时间戳
原理是R∩W≠NULL,因此读取半数的数据总是能够得到最新写入的值(通过时间戳最大来确定最新),多数派读写方案,带来了高可用、高可靠性,并且保证数据的一致性,但是存在事务性问题
- 非原子更新(写入操作没有进行分布式事务控制)
- 脏读(无法保证视图一致性,本质上也是分布式事务的一致性读)
- 更新丢失问题(无并发控制)
假设的分布式K-V存储系统
让我们假设一个存储系统具备下面的特点,
- 拥有三个存储节点的存储服务集群
- 使用多数派读写的策略
- 只存储一个变量”i”
- “i”的每次更新对应多个版本:i-1~i-n
- 这个存储系统支持三个命令 get 读取最新的 i set
设置下个版本的i值为 inc 对i加上 ,也生成一个新版本
在后续通过这个存储系统来演示多数派读写策略的不足,以及解决的方法。
命令实现:
set 直接对应多数派写 inc 简单的事务型操作
- 通过多数派读,读取最新的 i : i-1
- let i-2 = i-1 +n
- set i-2
单线程访问:
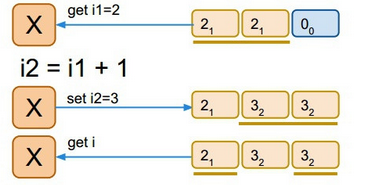
读取写入的时候,使用多数派准则。在单线程的模式下,读写正常。
如果出现并发访问的情况:
1
2
X进程读取i-1 并设置i-2 = i-1 + 1
Y进程读取i-1 并设置i-2 = i-1 + 2

如果顺序执行,应该期待最后的值为i-3 = 5,这需要Y知道X已经写入了i-2,因此如何实现这个机制是并发控制的关键。
在单机系统中,很容易提出使用锁来进行处理,悲观锁:保证不会失败;乐观锁:保证不会错误,以乐观锁为例:乐观锁使用类似update set val:$newval version:$version+1 where version = $version的操作语句,乐观锁在单机数据库事务的get and set场景中可以很好地应对。在数据内部同添加排他锁来保证update的时候,不会有其他的访问同时更新数据,加上乐观版本号控制,保证一个版本的数据只会被修改一次,从而避免更新丢失的问题。
但是单机系统的锁通过文件lock很容易实现,但是多个物理节点之间只能通过消息来进行通信,显然通过直接使用单机的lock模式是不可行的。
因此我们需要寻找一个方法,能够保证保存在多个存储节点中的某个版本只能一次成功写入,然后增加版本号、将写-写并发串行化,从而保证写-写模式下的一致性。
既,在X和Y的两次inc操作后,为了得到正确的i-3:
1
2
3
4
5
6
整个系统里对i的某个版本(i-2),只能有一次成功写入 可推广为:
在存储系统中,一个值(一个变量的一个版本)在被认为确定(客户端接到OK)之后,就不允许被修改。 最终问题转换为:
1. 确定一个值
2. 避免修改“被确定的”值
方案:每次写入一个值前,先运行一次多数派读,来确定这个值是否或者可能被写过了。
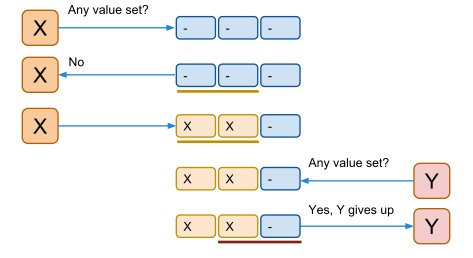
X询问时,多数派读得到值未被修改,X进行inc操作 Y询问时,多数派读得到值已经被修改,Y放弃操作
但是依然存在并发问题
如果X和Y同时以为还没有值被写入过,然后同时开始写
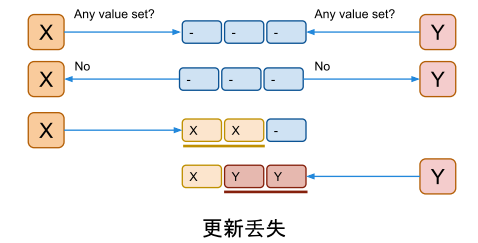
最终会有一个更新丢失 i-2 可能为 3 或者 4
方案的改进:会出现丢失更新的原因在于数据在第一次询问之后(确定可能被修改)之后,并没有给出锁定数据等待修改的保证。因此需要让存储节点记住谁最后一次做过“写前读取”,并给出承诺拒绝其他的“写前读取”的写入操作。

这里面,保证接受最后一次“写前读取”的过程,就是对“被确定值”不被修改的保证。作用等同于我们在单机事务中使用的排他锁的作用。不同的是,排他锁是通过本地的文件lock,而这边只能通过网络通信来进行保证。
总结起来,整个系统实际上是围绕着状态机(相同的起始状态,执行相同的命令会最终达到相同的终止状态)的概念来保证最后存储的一致性。每一个单独的存储节点本身是一个独立的状态机,节点内部存储的数据,按照其版本从小到打,构成一个抽象的Log,存储着历史上所有的值变更记录。只要保证Log以相同的顺序包含相同的值,也就是每个版本的数据都相同。在一些节点出现故障的时候,Log依然能够被正确复制和传播,那么所有节点组成的系统就构成了一个高可靠的状态机。
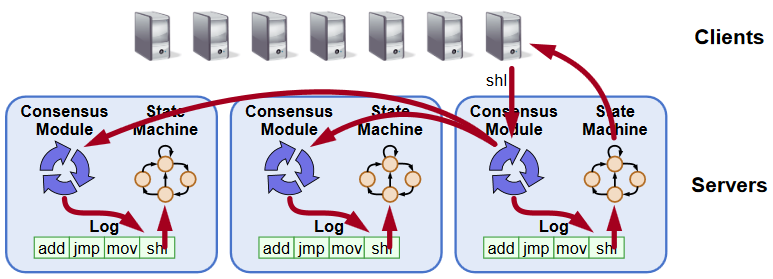
最终我们给出的一致性方案中,客户端和节点之间通过询问和保证的模式来确保已经确定的值不会被更改,通过多数派写/读的方式来确保数据最新的数据能够被存储和访问。从而保证了分布式一致性,这也是Paxos算法的雏形。
引用