快学Mybatis-背景介绍
Mybatis源自于ibatis,原本是Clinton Begin 创建的 JPetStore 项目中的 Dao 层,由两个部分组成 ibatis DAO 和 ibatis SQL Map,因为JPetStore的巨大影响,Ibatis也引起广泛的关注,到2004年 ibatis2 发布之后,Clinton将Ibatis捐赠给 Apache Software Foundation。2010年Ibatis的开发团队又从ASF迁出,将代码迁移如 Google Code,并基于 ibatis3 创建了 Mybatis 项目,之后 Google Code宣布关闭,目前 Mybatis 的代码托管在GitHub之上Mybatis-3。
Mybatis诞生的背景,也正是随着面向对象语言以及思想的兴起和流行,大量的系统使用诸如C++、Java、.NET以及Ruby等语言进行开发,在这些语言中,一个实体(entity)被抽象为一个类(class)。下面主要以Java作为编程语言进行描述。
在Java中,简单包含数据的抽象被称为POJO(plain old Java object 是一个简单的Java类,定义数据字段以及访问数据字段的getter和setter方法),其特点是简单,不依赖于特定的框架实现,例如:
1
2
3
4
5
6
7
8
9
public class MyBean {
private String someProperty;
public String getSomeProperty() {
return someProperty;
}
public void setSomeProperty(String someProperty) {
this.someProperty = someProperty;
}
}
在编程中使用POJO封装各种业务对象以及操作实体(Entity-Object),在简单的E-O模型下,将实体中的属性,定义为POJO中一个普通的字段(field),实体中具体的值则作为对应抽象出来的类的具体实现中的字段值,保存在程序运行环境中。
使用POJO来抽象实体,因为其简单和灵活可拓展,逐渐被使用面向对象编程语言的程序员所接受。
另一方面,在程序中使用的对象特别是业务数据的抽象对象,一般都会有持久化的需求,在这里我们狭义地理解为存储到关系型数据库管理系统(RDBMS)中。
关系型数据库构建在关系模型之上,抛开关系模型的复杂数学定义和推导,我们重点了解其中“表”的概念,Table表示一种关联关系,是以列(Column)和行(Row)的形式组织起来的数据集合(二维数组)。一般可以认为,Column是关系的模型或者属性,Row则是具体的关系值。在关系型数据库中,Column是预先定义好的称为Scheme,Row则是关系的表示,按照Scheme定义的格式,写入到Table中。
将现实中的数据实体(subject),存储到关系型数据库中需要进行实体-关系转换(Entity –Relation)。最简单的E-R模型下,只需要将实体的属性,抽象定义成列,将实体中各个属性的具体值作为行写入即可。
以上两段中分别表述了现实数据实体(Entity)分别在程序(面向对象语言编写的系统)中,以及持久化介质(关系型数据库)中的不同表示方式,对象(POJO)和关系(Table)。为了打通实体在程序中(Object)和数据库中(Relation)的关系,就产生了对象-关系映射模型(ORM)。
数据在关系型数据库和程序的差异也称为impedance mismatch(阻抗失谐),其复杂度超出了本文讨论的范围,有兴趣可以自行查阅相关的资料
下面介绍如何使用编码的方式来完成程序(Java)对数据库中数据的操作。
1
2
3
4
5
6
ResultSet resultSet = statement.executeQuery("select * from author");
while (resultSet.next()) {
System.out.println("author name : " + resultSet.getString("name_"));
System.out.println("author age : " + resultSet.getInt("age_"));
}
//忽略了Connection资源以及数据库数据的相关操作。
程序中通过JDBC提供的Connection和数据库建立连接,并使用Statement执行SQL语句获取ResultSet。可以看到,ResultSet的数据结构基本和数据库中的数据结构是相互对应的。getXXX方法的参数即为数据库中的列名或者索引号。通过ResultSet作为窗口,程序就能够操作数据库中的数据了。
ResultSet表示一组数据库数据集合,并默认在内部维护一个游标(Cursor),通过游标的向前滑动(调用next())方法,可以依次访问SQL从数据库中查询得到的数据集,ResultSet提供了getXXX的操作实现值的读取和类型的转换。Jdbc中只定义了ResultSet接口,实际的实现在不同的数据驱动或者数据源中都可以进行自定义。但是核心都是维护数据集合以及游标,并提供操作数据集的方法。
在面向对象的编程语言中,一般还会同时定义对应的数据对象(Object)
1
2
3
4
5
public class Author {
private String name;
private int age;
/*ignore setter and getter*/
}
我们更加愿意在编写程序的时候,使用Author对象而不是直接使用ResultSet来进行操作,因此我们会选择将ResultSet数据集合转换为Author数据对象。
1
2
3
4
5
6
7
8
ResultSet resultSet = statement.executeQuery("select * from author");
List<Author> authors = new ArrayList<>();
while (resultSet.next()) {
Author author = new Author();
author.setName(resultSet.getString("name_"));
author.setAge(resultSet.getInt("age_"));
authors.add(author);
}
在上面的代码中描述了ORM要完成的核心功能,就是将ResultSet中的每一行记录转换为一个Author对象。其本质是非常简单而有规律的一一映射操作。但是如果每个这样的映射关系都通过手工编码的方式来完成,就显得特别得笨拙也容易出现typo错误。
在编程世界,有规律的重复必然会产生自动化的方案。因此各种解决ORM问题的框架也应运而生。本文主要描述的Mybatis也是其中之一,其他比较有代表性的诸如Hibernate ,Spring JdbcTemplate 等也都从各个不同的角度出发,来解决ORM的问题,并拓展到解决整个程序数据访问层的问题。
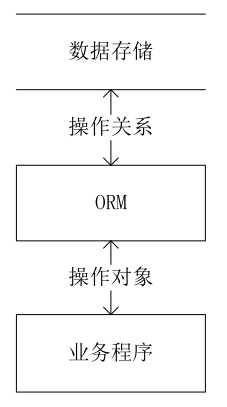
一般在引入ORM框架之后,所有对于数据库的操作都会通过ORM来完成。因此,虽然ORM框架是为了解决对象关系映射的问题而诞生的,但根据不同的产品出发点和目标,最终的实现往往比ORM这个单纯的映射操作来得复杂。