NGINX运行原理
NGINX
NGINX以轻量和高性能,备受推崇,本文主要记录我在使用NGINX过程中的一些体会。
进程模型
在工作中,NGINX一般是作为负载均衡的角色存在,高效和稳定是负载均衡的核心诉求,24G内存的NGINX机器的并发支撑可以达到百万级别,对于绝大多数的业务场景来说都已经足够。探知NGINX高效的秘密首先要从其进程模型说起。
NGINX默认情况下,使用Master+Workers的多进程模式,虽然也支持单进程和多线程的模式,但实际中很少使用,抽象的模型见下图。
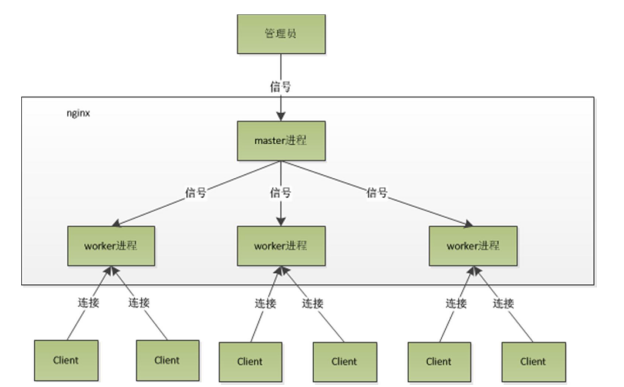
当启动一个4个worker进程的NGINX的时候,会创建一个master processor已经4个worker processor。
Master用于管理各个Worker进程,启动和控制NGINX只需要向master发送信号即可,如果修改了nginx.conf配置文件之后,向Master发送reload信号,会首先重新加载配置文件,然后启动新的worker集成,并向所有老的worker发送信号,告诉他们可以关闭,老的worker收到来自master的信号之后,不再接受新的请求,并在当前进程中处理的事件处理完成之后退出,实现了gracefully restart。大多数NGINX信号的处理过程也是如此。
worker之间是平等的,每一个进程,处理请求的机会也是均等的。首先每个worker都是从master进程fork出来的,在master进程里面,先创建好需要监听的socket(listenfd)之后,然后再fork出多个worker进程,因此多个worker监听的端口实际上是同一个,所有worker进程的listenfd会在新连接到来的时候变得可读,这个过程和epoll模型类型,也是通过事件回调完成的。
当一个请求到达操作系统的时候,监听这个端口的多个worker会被同时唤醒,为了保证每一个请求连接只会被一个worker进程处理,所有worker进程都需要在注册listenfd读事件之前先抢占accept_mutex,抢占到互斥锁的进程注册listenfd的读事件,在读事件处理中调用accept接受该连接。当一个worker进程在accept这个连接之后释放accept_mutex,并在自己的epoll中加入监听句柄,之后开始读取请求,解析请求,处理请求,产生数据之后,返回给客户端,最后断开连接。一个请求只会由一个worker来完成处理。
这样设计的优势
- 对于worker而言,独立的进程,不需要为处理过程添加锁,节约了锁的成本
- 便于排查问题,一个请求的整个处理过程,都只会对应到一个worker
- worker之间互相不会影响,一个进程退出只会,其他的进程依然可以正常处理,提高了系统的鲁棒性
- 充分利用多核心工作
事件处理
每一个worker只有一个主线程,能处理多少并发请求呢?我们知道网络模型分成典型的几种,同步堵塞,同步非堵塞,异步堵塞以及异步非堵塞,NGINX使用的是异步非堵塞模型。
让我们看看一个请求的在worker中的完整处理过程,请求发送过来,建立连接,接受数据,发送数据。具体到系统的底层,就是读写事件,当读写事件没有准备好的时候,是不可操作的。
对于堵塞调用,那就等待,等待事件准备好,再继续处理,堵塞调用会进入内核等待,cpu资源会让出给其他程序使用,对于单进程的worker来说,显然不合适,当网络事件越来越多的时候,大家都在等待,cpu空闲的时候,也没有人能使用,自然无法处理高并发。一个解决的方法就是增加进程数,但是却增加了更多的cpu上下文切换,在NGINX中,应该尽量避免堵塞的系统调用。
非堵塞调用,事件没有准备好,马上返回EAGAIN,让你稍后再过来检查事件,在这期间你可以先去完成其他的工作,这样虽然不堵塞了,但是却需要频繁进行轮询事件状态,因此诞生了异步非堵塞的事件处理机制,具体到操作系统中就是select/poll/epoll/kqueue这样的系统调用,这些框架提供了一种机制,让你可以同时监控多个事件,调用他们是堵塞的,但是可以设置超时时间,如果还没有事件准备好,就返回。
以Linux系统中应用最为广泛的epoll为例子,新进的socket会添加到epoll内部的一个rb-tree中,并注册回调函数,当socket的读写事件就绪之后,会调用回调函数,将读写事件添加到epoll内部就绪列表中,当调用epoll_wait的时候,直接将就绪列表中事件返回。
这样的并发请求模型模型,实际上处理请求的线程只有一个,所以同时能处理的请求自然只有一个,只是在各个请求之间不断切换,切换也是因为异步事件没有准备好,主动让出,不需要堵塞,代价也很小。可以理解未循环处理多个已经准备好的事件。和多线程相比,这种事件处理模型,不需要创建线程,每个请求占用的内存很少,也没有上下文的切换,事件处理非常轻量级,并发再多也不会导致无谓的资源浪费——处理器上下文切换。在内存足够的前提下,主要的成本是维护epoll树的内存成本增加。这也是NGINX高效的主要原因。
因此设置worker数量的时候,建议设置为cpu的核心数,就很容易理解了,更多的worker会导致进程竞争cpu资源,带来更多的上下文切换,NGINX提供了cpu亲缘绑定选项,可以将某一个进程绑定到某一个核心上,这样可以进一步提高性能,因为cpu可以更多利用寄存器和cpu缓存,可以使用worker_cpu_affinity进行绑定。
信号处理和定时器处理
NGINX在等待epoll_wait的时候,如果程序收到信号,在信号处理函数完成后,epoll_wait会返回错误,然后程序可以再次进行epoll_wait调用。
定时器处理,epoll_wait可以设置调用的超时时间,NGINX借助这个超时事件来实现定时器,定时器一般的应用是在一些规定时间内要求完成的请求,比如带有时间限制的请求等。每次进入epoll_wait之前,会先从内部维护定时器事件的rb-tree中拿到所有定时器时间中的最小时间,在计算出epoll_wait的超时时间之后进入epoll_wait,当没有事件发生,也没有中断信号(如果计算得到后是负数,则表示已经超时了),epoll_wait就会超时,也就是定时器时间已经到了,这个时候,NGINX会检查所有的超时时间,设置为超时,然后去处理网络事件,当我们自己编写NGINX代码的时候,在处理网络事件的回调函数时,第一件事情是判断超时,如果超时则讲事件标记为超时,然后再去处理网络事件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
while(true) {
for t in run_tasks:
t.handler();
update_time(&now);
timeout = ETERNITY;
for t in wait_tasks:
if (t.time <= now) {
t.time_handler();
} else {
timeout = t.time - now;
}
nevents = poll_function(events,timeout);
for i in nevents:
task t;
if (nevents[i].type == READ) {
t.handler = read_handler;
} else {
t.handler = write_handler;
}
run_tasks_add(t);
}
从上面的伪代码就可以很容易得到定时器的处理方式。
Connection
最后再说一下connection的概念,在NGINX中Connection就是对tcp连接的封装,其中包括连接的socket,读事件,写事件,利用NGINX封装的Connection,我们可以很方便地处理连接相关的事情,比如建立连接,发送和接受数据,而NGINX中的http请求处理就是建立在Connection之上,所有NGINX不仅可以作为一个web服务器,也可以作为邮件服务器,利用Connection,我们可以实现和任何后台服务打交道。NGINX 1.9引入的stream就可以实现tcp级别的4层负载均衡。